Pitch Estimation using Deep Learning
I recently published a paper on using Deep Learning to estimate fundamental frequencies of overlapping harmonics The paper was included in the proceedings of the 2021 IEEE WNYISPW on IEEE Xplore. The conference was hosted at the Rochester Institute of Technology.
The neural network architecture chosen is based on processing only the frequency domain signal with a single FFT. Our approach uses constant Q transform (CQT) to convert the linear frequency scale to a logarithmic frequency scale. In audio signal processing, this is often called mels or the mel scale. In the mel scale, harmonics are equally spaced regardless of fundamental frequency.
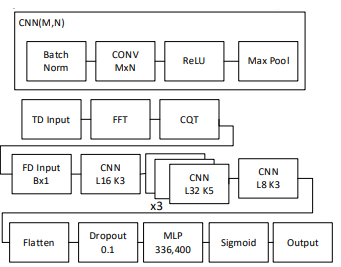
Deep Network Architecture and preprocessing blocks
Following pre-processing using FFT and Constant Q Transform, the signal is passed through this Deep Neural Network. This network uses a sequence of convolutional blocks with varying number of layers and kernel size. A sigmoid function scales the output likelihood to a range (0,1).
The model is trained with CQT as an input, represented as a vector of floats. The network outputs a vector of likelihoods where each bin is a specific fundamental frequency and loss is computed against a boolean vector the same size.
One issue with this representation of the signal is that it is very sparse. Typically a signal only has a few fundamental frequencies, so there are lots of empty bins. Our approach to resolve this using weighted binary cross-entropy loss.
\[BCE_{weighted}(p,\hat p) = -\beta _2 p log(\hat p ) - \beta _2(1-p) log(1- \hat p )\]We choose \(\beta _1\) and \(\beta _2\) based on the expected imbalance of the distributions.
\[\frac{\beta _1}{\beta _2} > 1\]You can read a copy of the paper here for more details.